نوشته های مرتبط




چکیده: در این پست، ما در مورد تعدادی از Best Practiceهای سلنیوم برای اتوماسیون تست سلنیومی بحث میکنیم که ممکن است به شما در توسعه Test Suiteها یا Test Caseهای خوش طرح و البته مقیاس پذیر کمک کنند.
در طول کار خود در تست اتوماتیک با استفاده سلنیوم، با افراد زیادی روبرو شدهام که از پایداری و اطمینان اتوماسیون تست خود شکایت دارند. در بیشتر موارد، منطق مورد استفاده در اجرای Test Caseها مناسب بود، اما شیوه طراحی و Scalability(مقیاسپذیری) نگران کننده مینمود.
پس از مدتها کار با چارچوب سلنیوم، فهمیدم که رویکرد “یک سایز برای همه” در مورد اتوماسیون تست سلنیومی صدق نمیکند. اگرچه هیچ قاعده سرانگشتی برای طراحی و توسعه تستهای اتوماتیک مقیاسپذیر وجود ندارد، اما اصول خاصی وجود دارد که باید هنگام نوشتن تستها با استفاده از چارچوب سلنیوم رعایت کنید. این اصول میتوانند ” Best Practiceهای سلنیوم” باشند.
در این پست، ما در مورد تعدادی از Best Practiceهای سلنیوم برای اتوماسیون تست سلنیومی بحث میکنیم که ممکن است به شما در توسعه Test Suiteها یا Test Caseهای خوش طرح و البته مقیاس پذیر کمک کنند.
صرف نظر از زبانی که برای اتوماسیون تست با سلنیوم استفاده میکنید، این موارد Best Practiceهای ارزشمند سلنیوم هستند.
- بهترین مکانیسم مکانیابی را انتخاب کنید
یکی از چالشهای اتوماسیون تست در سلنیوم این است که اگر تغییراتی در عملکرد مربوط به مکانیابهای(Locator) استفاده شده در کد تست وجود داشته باشد، باید تستهای اتوماتیک اصلاح شوند. ID, Name, Link Text, XPath, CSS Selector و غیره برخی از Locatorهای وب هستند که در Selenium WebDriver اغلب استفاده میشوند.
با وجود تعداد زیادی از Locatorهای وب، لازم است یکی از موارد مناسب را انتخاب کنید تا تأثیرپذیری تستها به دلیل تغییر در UI به حداقل برسد. در صورت وجود وضعیت پویا یا همان داینامیک، معمولاً Link Text ارجح است. ممکن است شما تصور کنید استفاده از ID، و Name ایمنتر هستند. بله. در شرایط معمول استفاده از این دو Locator پیشنهاد میشود. اما در شرایط داینامیک، Name و ID ممکن است، در لحظه، توسط سیستم تولید شوند. این یعنی مقادیر آنها یک بار مصرف است، و با اجرای مجدد کد خواهید دید که Web Elementها با استفاده از آنها قابل پیدا کردن نخواهند بود. اما چرا Link Text را پیشنهاد میکنیم؟ Link Text معمولا یا ثابت است و یا بواسطه یک Data Entry توسط کاربر ایجاد شده است، و این یعنی شما در هر صورت میدانید که متن این Link چیست. فلذا Link Text قابلیت Locating بسیار بالاتری نسبت به موارد مذبور دارد. البته دقت کنید که من از واژه “معمولا” استفاده کردم. و این یعنی، شرایط همیشه به این صورت نیست.
خود من اکثر اوقات وقتی به مشکلی در یافتن Web Elementها برخورد میکنم، XPath را بر دیگر روشها ترجیح میدهم. البته این کار معمولا از سر عادت و تنبلی است. اما XPath هم مخاطراتی دارد، هر چند گاهی اوقات تنها راه باقیمانده شما استفاده از XPath است. اما مخاطرات XPath عبارتند از:
- موتورهای XPath یا همان XPath Engineها ممکن است از یک مرورگر به مرورگر دیگر متفاوت باشند. از این رو، هیچ تضمینی وجود ندارد که XPath برای یک مرورگر، به همان شکل برای مرورگر دیگر هم کار کند. مرورگری مانند Internet Explorer دارای موتور XPath بومی برای مکانیابی عناصر وب نیست. به همین دلیل، معمولا از JavaScript XPath Query Engine برای یافتن عناصر توسط XPath در اینترنت اکسپلورر یا همان IE استفاده میشود. این مکانیسم، نسبت به موتور XPath بومی کندتر خواهد بود.
- XPath مکانیسمی شکنندهتر نسبت به باقی مکانیسمهای مکانیابیست. زیرا مرتب سازی مجدد عناصر در یک صفحه یا معرفی یک عنصر وب جدید میتواند باعث شود که پیاده سازی موجود Test Script با XPath از کار بیفتد.
- اگر XPath تنها گزینه است، گاهی اوقات باید از XPath Absolute و گاهی اوقات از Relative XPath استفاده کنید. از آنجاییکه Relative XPath از Anchor استفاده میکند، میتواند تا حد زیادی سلسله مراتب ساختاری را ندیده بگیرد، و Web Element شما را بیاید. اما اگر مثلا در صفحه شما یک ID داینامیک وجود داشته باشد، آنگاه به دلیل استفاده از این ID در Relative XPath، خواهید دید که در فراخوانیهای بعدی روی Test Script خود، Relative XPath شما را به جای هدایت به سمت Web Element به نا کجا آباد رهنمون میشود، و در نهایت شما را با No Such Element Exception مواجه خواهد نمود. اما نگران نباشید به مرور زمان، در استفاده از XPath به مهارت خواهید رسید.
ترتیب ایده آل برای استفاده از مکانیسمهای مکانیابی بدین گونه است:
- ID
- Name
- CSSSelector
- XPath
- یک ماتریس سازگاری مرورگر برای Cross Browser Testing ایجاد کنید
Cross Browser Testing یک کار چالش برانگیز است زیرا شما باید اولویت را برای تست در ترکیبات مختلف مرورگر + سیستم عامل قرار دهید. اگر مرورگرها و نسخههای آنها را در تستها بگنجانیم، تعداد تستها بسیار زیاد خواهد شد. رسمیسازیِ(Formalizing) لیستی از ترکیبات (مرورگر + سیستم عامل + دستگاه) از اهمیت بالایی برخوردار است. زیرا در اولویتبندیِ ترکیباتی که باید برای Cross Browser Testing استفاده شوند، کمک میکند. این لیست رسمی Browser Matrix یا Browser Compatibility Matrix نیز نامیده میشود.
Browser Matrix اطلاعاتی حیاتیست که از تحلیل محصول(Product Analytics)، موقعیت جغرافیایی و سایر اطلاعات دقیق در مورد الگوهای استفاده مخاطب، آمار و تحلیل رقبا استخراج شده است. Browser Matrix به شما کمک میکند تا تمام مرورگرهای مربوطه(که برای محصول شما مهم هستند) را پوشش دهید، در نتیجه تلاشهای توسعه و تست را کاهش میدهد. یک نمونه ماتریس سازگاری مرورگر در زیر آمده است:
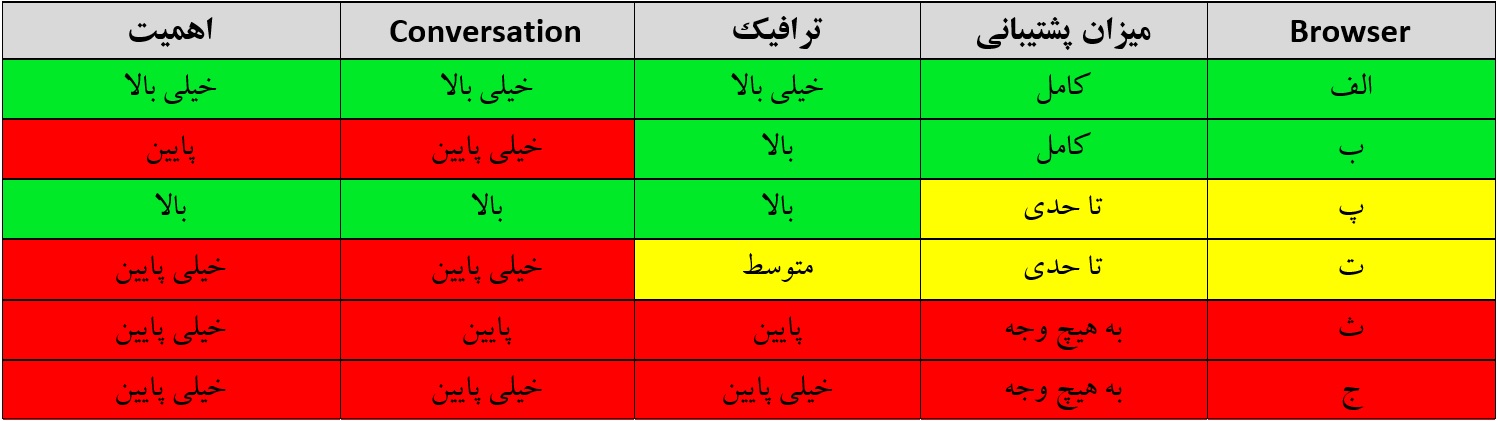
طراحی این ماتریس قاعده خاصی ندارد. بلکه بر حسب تجربه میتوانید آنرا تولید کنید. اما آنچه که اهمیت دارد این است که شما باید حداقل چهار پارامتر را در این ماتریس در نظر بگیرید:
- Browser
- میزان پشتیبانی که توسط سازنده Browser از آن صورت میگیرد
- ترافیکی که روی وب اپلیکیشن خود در این Browser دارید
- میزان Conversation و تعاملی که کاربران با وب اپلیکیشن شما در این Browser دارند. ممکن است تفاوت بین مورد ترافیک و Conversation برای شما سوال شود. خیلی ساده است. گاهی اوقات ممکن است درخواست اتصال به سایت شما زیاد باشد، اما کاربران خیلی به زیر و بم سایت شما ورود نکنند. درخواست اتصال به سایت همان ترافیک و تعامل با قسمتهای مختلف سایت Conversation است.
- گزارشگیری و لاگ برداری
اگر یک تست خاص در یک Test Suite بزرگ به نتیجه نرسد، تعیین محل تست ناموفق و اینکه اصلا چرا این تست در مجموعه تستهای شما Fail شده است، میتواند چالش برانگیز باشد. در چنین شرایطی لاگ برداری میتواند یک نجات دهنده بزرگ باشد، چرا که لاگهای کنسول در مکانهای خاص در کدِ تست، به توسعه یک درک بهتر از کد و همچنین در به صفر رساندن مشکل کمک میکند. لاگ برداری چیزی متفاوت با گزارشگیریست. لاگ برداری یعنی اینکه شما در زمان یا پس از اجرای کد خود بتوانید لحظه به لحظه اجرای کد را رصد کنید. معمولا لاگها در لاگ فایل ثبت میشوند. مثلا اگر شما از جاوا به همراه سلنیوم استفاده میکنید، میتوانید برای لاگ برداری از Log4j استفاده کنید.
همراه با لاگ برداری، گزارشگیری نیز بخشی جدایی ناپذیر از اتوماسیون تست با سلنیوم است، زیرا به تعیین وضعیت(Pass/fail) برای تست، کمک میکند. اینجا، همان جاییست که گزارشات تست اتوماتیک میتواند نقش بزرگی را ایفا نماید، چرا که به شما در پیگیری پیشرفت Test Suite(یا Test Caseها) و Test Resultهای مربوطه کمک میکند. گزارشات همچنین به دلیل بهبود در خوانایی خروجی تست، در به حداقل رساندن زمان مورد نیاز برای نگهداری دادههای تست کمک میکنند. بعلاوه با استفاده از تست اتوماتیک، تحلیل Featureها و دستیابی به Test Coverage با استفاده از گزارشات آسان میشود.
اتوماسیون تست سلنیومی بدون لاگ برداری و گزارشگیری، فقط هدف بهرهگیری از چارچوب سلنیوم را شکست میدهد. به همین دلیل لاگ برداری و گزارشگیری یکی از Best Practiceهای تست در اتوماسیونِ سلنیومی است.
و این مقاله ان شا ا… ادامه خواهد داشت…
![]()

