نوشته های مرتبط




خلاصه: تنها در یک سال، یک تیم تست، چرخه تست خود را بیش از ۵۰ درصد کاهش داد. این کار مستلزم تحلیل، برنامهریزی و تلاش است. آنها در ابتدا به این نکته توجه کردند که چگونه زمان خود را صرف میکنند و از خود پرسیدند که آیا در هیچ کدام از زمینههای کاری خود میتوانند زمان را کاهش دهند یا خیر؟ به محض آنکه متوجه شدند در کجا میتوانند مفیدتر واقع شوند، توانستند از عهده موانع سر راهشان برآیند. در این مقاله روشی که شما هم میتوانید در این راستا از آن بهره ببرید ارائه شده است.
بدبخت شدیم؟!
این همان واکنشی بود که از تیم سر زد؛ هنگامی که به آنها گفتم آیا ممکن است زمان تست را یک هفته تسریع کنند!
در این پروژه، به طور معمول یک چرخه تحویل ۹ ماهه را داشتیم که از مجموع این مدت، ۳ ماه(پس از تکمیل شدن کد) را به تست سیستم اختصاص میدادیم، و البته از تمامی روزهای آن سه ماه هم برای تست استفاه میکردیم. در هفتههای پایانی تحویل، شبها و آخر هفتهها را هم کار میکردیم. طی ملاقاتی که با تیم داشتم، به دلایل مختلف وجود یک بازه یک هفتهای افزون بر زمانبندی اولیه احساس شد. پس رویه دیگری را در پیش گرفتیم. به این صورت که زمانی را به این موضوع اختصاص دادیم که زمان خود را طی این ۱۲ هفته(۳ ماه) باید صرف چه کارهایی کنیم. بدین ترتیب شروع به لیست کردن تمامی کارهایی کردیم که باید طی این مدت انجام میدادیم. در آخر به چیزی شبیه به یک فرمول رسیدیم که زمان را مدلسازی میکرد:
مدت زمان تست سیستم=RC*(TC/TV+B*BHT)/PC
- RC = تعداد چرخههای تست مجدد یا اینکه ما چند بار به دلیل تغییرات در برنامه، تست مجدد انجام میدهیم
- TC = تعداد Test Caseهای اجرا شده در هر چرخه
- TV = سرعت تست، یا به طور متوسط، تعداد Test Caseهای اجرا شده در یک واحد زمانی
- B = تعداد باگهای یافته شده و تصحیح شده در خلال فاز تست
- BHT = زمان مدیریت باگها، یا میزان تلاش صورت گرفته روی هر باگ(تشخیص، مستندسازی، تأئید رفع خطاها و غیره)
- PC = ظرفیت نفری، یا تعداد افراد در حال تست با درنظر گرفتن بهرهوری
اکنون مدل خود را به عنوان راهی برای فشردهسازی زمان به روشی سادهتر داریم. میتوانستیم سوالات مهم دیگری بپرسیم، مثل موارد زیر:
- برای کاهش تعداد چرخههای تست مجدد چه میتوانیم بکنیم؟
- آیا نیاز به اجرای تمام Test Caseها داریم؟
- چگونه میتوانیم سرعت تست را افزایش دهیم؟
- چگونه میتوانیم تعداد باگهایی که با آن در طول فاز تست سر و کار داریم را کاهش دهیم؟
- آیا با مدیریت باگها بهرهوری بیشتری خواهیم داشت؟
- از کجا میتوانیم افراد بیشتری را برای کمک به تست پیدا کنیم و چگونه میتوان این افراد را کاراتر کرد؟
زمان صرف شده با شکستن این مشکل بزرگ و بیریخت به سوالات عملی بیشتر، به ما کمک کرد تا ببینیم که واقعا میتوان تفاوت ایجاد کرد. این یعنی ما بیچاره و سردرگم نبودیم.
مجددا جلسات را با پرسیدن فقط یکی از سوالات شروع کردیم و سپس راههایی را برای بهبود تنها همان متغیر کشف کردیم. در نهایت، پس از گذشت یک سال از پیشرفت پروژه، قادر به کاهش زمان تست سیستم به پنج هفته شده بودیم(به خاطر داشته باشید که زمان تست اولیه ما ۱۲ هفته بود). زمانی که صحبت درباره این موضوع را آغاز کردیم فکر نمیکردیم که حتی بتوانیم یک روز از دوازده هفته چرخه تست را حذف کنیم، اما با کاهش زمانی به بیش از نصف، کار را به اتمام رساندیم.
کاهش باگها در تست سیستم
ما با تعداد باگهایی که در طول تست سیستم یافته بودیم شروع کردیم. به دلیل آنکه باگهای زیادی را کشف و رفع کرده بودیم، فرصت خوبی برای بهبود وجود داشت. اما کاهش باگها برای هدف اصلی ما که ارائه نرمافزار با کیفیت بالا بود بسیار مهم مینمود.
با درنظر داشتن این نکته، دلایل و عوامل اصلی باگهای یافته شده در تست سیستم را ثبت و ضبط نمیکردیم(یعنی به دلیل مشکلات سنگین و کمبود زمان اصلا به آن فکر هم نکرده بودیم) بنابراین مجبور بودیم از قضاوت و همکاری با تیم توسعه استفاده کنیم. نمونهای از باگهای یافته شده در چرخه تست قبلی را خواندیم و هر نوع الگویی برای رسیدن به دلایل این باگها را دنبال کردیم. تعدادی خطای سادۀ کدنویسی و Memory Leak(نشت حافظه) را یافتیم( برنامه به زبان ++C بود). زمانی به این موضوع اختصاص دادیم که در آن مطمئن شویم حداکثر Review را روی کد خود انجام دادهایم تا بدین ترتیب به کاهش خطاهای موجود در کد کمک کنیم. آموزش Code Review، پیگیری Code Review(که آیا مشکلات یافته شده مرتفع گردید یا خیر) و گزارش نتایج Code Review سه موضوعی بود که برای تیم جا انداختیم. همچنین ابزارهایی استفاده کردیم که برای تشخیص Memory Leak طراحی کرده بودیم. این دو بهبود در تلاش برای مقابله با باگها در طول تست سیستم آغاز شد. خوشبختانه، ثبت و ضبط عوامل و دلایل ریشهای باگها را نیز آغاز کردیم و تحلیلی منظم برای یافتن فرصتهای دیگر برای رسیدن به بهبود انجام دادیم.
بهبود زمان مدیریت باگ
وقتی که به لیست باگهایمان نگاهی انداختیم متاسف شدم که دریافتم نیمی از باگهای گزارش شده بدون درست شدن، بسته شده بودند و دیگر مورد پیگیری قرار نگرفته بودند. دو مورد از بزرگترین فاکتورهای مرتبط این بود که توسعه دهندگان نمیتوانستند باگ را مجددا تولید کنند و یا باگ یک نمونه تکراری از باگ دیگری بوده که قبلا در سیستم وجود داشته است.
این امر نیازمند یک تغییر ساده بود: تیم تست را برای جستجو در سیستم Bug Tracking قبل از درج باگ جدید آموزش دادیم. اگر آنها یک باگ مشابه پیدا میکردند، باید به گزارش اصلاح باگ با اطلاعات به روز شده مراجعه میکردند و یا با توسعهدهنده اختصاص داده شده به آن باگ مشورت مینمودند.
برای باگهایی که قابل تکرار نبودند، یک امتحان انجام دادیم. به جای آنکه تستر باگ را بنویسد و به جلو حرکت کرده و ادامه دهد، تستر “Bug Huddle” را نگه میداشت تا باگ را به تیم توسعه نشان دهد. این Bug Huddle معمولا در انتهای روز رخ میداد. پس از آن تستر Test Report را پس از گفتگو با توسعهدهنده مینوشت. این امر منجر به Bug Fixهای سریعتری میشد. آنچنان که توسعهدهندگان اغلب میگفتند که:” اَه، حالا فهمیدم چه اتفاقی افتاده”. بدین ترتیب نمایش باگ برای کاهش ابهامات موجود در مراحل تولید مجدد باگ راه درازی را طی میکرد.
پس از این بهبودها، دیدیم که بیش از هشتاد درصد از باگهای گزارش شده واقعا درست شده بودند و روال”باگ پینگ پونگی”(باگهایی که مرتب میروندو میآیند) نیز کمتر شد.
افزایش سرعت تست
به نظر میرسید افزایش پوشش اتوماسیون تست منجر به افزایش سرعت تست شود، و البته همینطور هم شد. اتومات کردن واقعا توانست به این امر کمک کند. اما مسائل دیگری نیز برای بهبود سرعت پیدا کردیم. ابزارهایی ساختیم که نمونه نسخه را نصب میکرد، و دادههای تستی(Test Data) را نیز به صورت اتوماتیک درج مینمود. بنابراین تسترها وقتی که صبح برای شروع کار میرسیدند نمونهای از نسخه نصب شده را داشتند که در آن Test Dataها قبلا در جای خود قرار گرفته بودند.
همچنین لیستی با عنوان”بیشترین میزان درخواست برای رفع باگها” ساختیم و اولویت این باگها را نیز در آن مشخص کردیم. باگهایی که بیشترین درخواست را برای رفع داشتند آنهایی بودندکه مانع انجام کامل تست میشدند. به همین دلیل اولویتی که توسعهدهندگان استفاده میکردند را به بهرهوری تسترها گره زدیم. این کار به کاهش زمان انتظار تسترها که باید منتظر رفع باگ میماندند منجر شد.
کاهش Test Caseها
ایده کاهش تعداد تستهایی که اجرا کردیم، در زمان شروع به فکر کردن راجع به آن کاملا بحث برانگیز بود. اما زمانیکه این موضوع را به شکل تست مبتنی بر ریسک در نظر گرفتیم(یعنی تستی که در آن تلاش بیشتر برای جای پر ریسکتر است) روند ما پیشرفت را آغاز کرد.
هر Test Suite را در دو بعد رتبهبندی کردیم: اول شدت مشکل و دوم احتمال بروز یک مشکل. هر دو بعد را به سه دسته بالا، متوسط و پایین تقسیم کردیم. حاصل تلفیق این دو بعد امتیازی را به یک باگ میداد(به صورت P1، P2، P3) که میزان اولویت را مشخص میکرد. P1 بالاترین اولویت و P3 پایینترین اولویت.
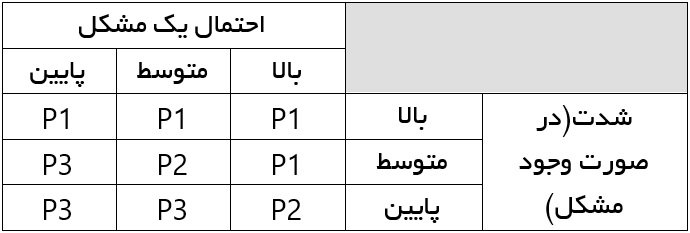
ما این تحلیل را با تیم توسعه مرور کردیم و از آنها راجع به نواحیای که به نظرشان دارای ریسک بیشتری بودند سوال کردیم. آنها بلافاصله قادر به نام بردن برخی از نواحی بودند و همچنین تحقیقاتی را درباره تغییرات log برای کدی که اخیرا در آن رفع باگ صورت گرفته بود، انجام دادند. ما این اطلاعات را با تیم مدیریت محصول برای ارزیابی تأثیر روی مشتری در سطح شدت مورد بررسی قرار دادیم. به همین ترتیب تحلیلی مداوم را مبنی بر استفاده از سیستم با استفاده از پارامترهای آماری صورت دادند.
Test Suiteهای با اولویت P1 بیشترین میزان اولویت را برای تست داشتند. با این اوصاف از قسمتهایی که باید هر چه سریعتر در چرخه تست نرمافزار، تحت آزمون قرار میگرفتند اطمینان حاصل کردیم، و بعد از آن اطمینان مییافتیم که هیچ رگرسیونی در طول چرخه روی این باگها وجود ندارد.
Test Suite با اولویت P2، اولویت بعدی بود و آزادی عمل بیشتری بر روی تست رگرسیون در انتهای چرخه داشتیم. برای Test Suite با اولویت P3، آنها را به طور جزئی مورد تست قرار میدادیم و Test Suiteها را صرفا با استفاده از یک نمونه تست میکردیم.
یافتن افراد بیشتر
این بهبود را به عنوان آخرین بهبود در نظر گرفتم چون اولین چیزی بود که تیم برای آن درخواست داده بود، یعنی: تیم بزرگتر.
در ابتدا نگران درخواست بودجه بیشتر برای افراد بودیم و نمیخواستیم بیشتر از این به دنبال بودجه باشیم. اما بعد از ایجاد برخی بهبودهای اشاره شده در بالا و نشان دادن میزان پیشرفت، مدیرمان از ما پرسید که چه کارهای دیگری میتوانستیم انجام دهیم.
ایجاد بهبودهای قابل نمایش، خود یک سرمایهگذاری در زمان تیم محسوب میشود. ما قادر شدیم برای جذب افراد بیشتر درخواست دهیم و نشان دهیم بهبودهای بیشتر با سرمایهگذاری جدید حاصل میشود. ما همکاران غیرمقیم جدیدی برای کمک به حجم بالای تست رگرسیون خود پیدا کردیم. این کار به تیم موجود زمان بیشتری داد تا بهبودهای بیشتری ایجاد کنند که منجر به نائل شدن به چرخه بهتری میشد.
قبل از عقد قرارداد با همکاران جدید، برای همکاری در برخی از تستها، کمکی کوچک از جانب همکاران دیگرمان در سازمان گرفتیم. مدیران محصول، پشتیبانی مشتریان و تیم مستاندسازی فنی واقعا برای کمک به ایجاد یک محصول بهتر سرمایهگذاری میکردند و وقت خود را برای کمک به تست خالی مینمودند.
ما همچنین روش Bug Hunting را ایجاد کردیم. ما به افرادی که باگهای جالب یا شدید را پیدا میکردند، جایزه میدادیم. این موضوع باعث شد تا افراد زیادی برای تست به عنوان فعالیت جانبی و سرگرم کننده از جاهای دیگر سازمان وارد عمل شوند.
نبردتان را انتخاب کنید
در انتها، زمان تستمان را از دوازده هفته به پنج هفته کاهش دادیم. این کار کار آسانی نبود اما با یک بار ساختن چنین معادلهای برای نمایش زمان و آغاز جداسازی هر متغیر، توانستیم با موفقیت چالشهایمان را به پایان برسانیم.
در طول این پروژه، بارها از این تکنیک برای شتاب دادن به چرخه تست استفاده کردیم. تیمها حقیقتا مایل به شکستن زمان به متغیرهای خاص و یافتن فرصتهایی برای ایجاد بهبودهای دقیق بودند.
از خود بپرسید تیم شما چگونه میتواند سریعتر کار کند؟
![]()

