نوشته های مرتبط




خلاصه: پوشش تست(Test Coverage) یک معیار مهم در مدیریت تست است که با پیشرفت فنآوری، ما را قادر خواهد ساخت تا از روند جدیدی برای پیشبینی پوشش استفاده کنیم. Weka یک مجموعه یا سوییت متن بازِ(Open Source) یادگیری ماشین است، که میتواند مدیریت تست را، فراتر از صفحات گسترده(Spreadsheet) و البته با آخرین فنآوریهای هوش مصنوعی انجام دهد و همچنین این امکان را فراهم میکند که پیشبینی تست زودتر از موعد و با دقت بیشتری انجام شود.
در این راستا بهتر است که تسترها درگیر مرحله جمعآوری نیازمندیها(Requirement) در چرخه توسعه نرمافزار شوند، زیرا این موضوع در جهت درک بهتر نیازمندیها، به نفع تیمهای تضمین کیفیت و Business خواهد بود. ما این نیازمندیها را تحلیل کرده، Test Caseها را تهیه و اجرا نموده، اشکالات را ردیابی(Tracking) کرده، و در آخر برای استخراج و تائید Test Coverage اقدام میکنیم.
یکی از شرکتهایی که مدتی در آنجا مشغول به کار بودم، یک آژانس تجارت دیجیتال بود. و در ارتباط با فنآوریهای تجارت الکترونیک فعالیت داشت که مشتریان سازمانی را سرویسدهی میکرد. در چنین وضعیتی پوشش تست به عنوان یک معیار ضروری برای سنجش کیفیت پروژهها محسوب میشد. مدیریت تست ما، در ابتدا از طریق صفحات گسترده انجام میشد که در بحث نگهداری این صفحات و پیچیدگی استخراج اطلاعات و منسوخ شدن دادهها، منجر به بروز مشکلات عدیدهای گردید.
پس ما برای کار از یک صفحه گسترده به اشتراک گذاشته شده گوگل(Shared Google Spreadsheet) در محیط مشترک استفاده کردیم. هرچند، این مورد، منجر به حذف و یا اصلاح تصادفی برخی محصولات کاری ما شد، اما این تنها پیامد منفی این استراتژی نبود چرا که آمادهسازی گزارشها و ارائه پروژهها به سهامداران و ذینفعان منجر به صرف زمان بیشتری از زمان تست نرمافزار میشد.
در این زمان تصمیم گرفتیم تا روی ابزارهای مدیریت تست تحقیقاتی به عمل آوریم. این ابزارها در طول سالها، تکامل یافته و برخی از مشکلات ما را در ارتباط با ویژگیهایی مانند دسترسی مبتنی بر نقش، استفاده مجدد از محصولات کاری، نظارت بر فعالیتهای تست و گزارشهای سفارشی حل کرده بوند. این ابزارها همچنین به ما در حفظ Best Practiceها کمک کرده و منجر به مدیریت موثر رهبران تست در سطوحی بالاتر میشدند.
با این حال، آنها هنوز هم توانایی پیشبینی مواردی مانند برآورد تست(Test Estimation)، پوشش تست(Test Coverage) برای ریلیز و مشکلات کیفی را نداشتند و مدیران تست، هنوز هم زمان زیادی را صرف بررسی دستی پیشبینیهای ترکیبی آماری تولید شده با استفاده از گزارشات ابزارهای مدیریت تست میکردند. به همین دلیل ما مجبور به یافتن فنآوری دیگری برای نظارت و پیگیری پیشرفت زمانبندی پروژه شدیم.
برای حل این مشکل ما Weka را یافتیم
محیط Waikato مربوط به تحلیل دانش(Knowledge Analysis) است. Weka یک مجموعه یا سوییت متن بازِ(Open Source) یادگیری ماشین است که مناسبِ کارهای داده کاویست که توسط دانشگاه Waikato، نیوزیلند ساخته شده است. این نرمافزار با یک UI آسان در دسترس بوده و شامل Libraryایست که در مقایسه با سایر ابزارها، برای مبتدیان در یادگیری ماشین و هوش مصنوعی بسیار مناسب است. این الگوریتمها میتوانند به صورت مستقیم از طریق یک مجموعه داده(Data Set) خوانده شده و یا از کد جاوای پروژه در این زمینه استفاده کنند.
در ادامه به بررسی چهار ابزار اصلی در Weka UI که قابلیت انتخاب دارند، پرداخته میشود:
- Explorer اولین رابط کاربر گرافیکی است که به شما امکان دسترسی به اکثر قابلیتها را میدهد.
- Knowledge Flow این امکان را برای شما فراهم میآورد که اطلاعات را پردازش، مشاهده و بصریسازی(Visualize) نمایید.
- Experimenter به شما کمک میکند تا به سوالات پاسخ دهید، مانند اینکه یک طبقهبندی در یک مجموعه داده خاص از دیگری بهتر است.
- Workbench که از یک UI یکپارچه برای Weka استفاده میکند.
Weka دارای گزینههای متعددی برای تولید پیشبینیها از هر نوع داده است. در اینجا، ما از Libraryهایمان برای پیشبینی Test Coverage استفاده میکنیم.
پیشبینی Test Coverage در Weka
Weka Explorer یک UI آسان است که با استفاده از آن قدرت نرمافزار یادگیری ماشین Weka تحت کنترل قرار میگیرد. هر یک از Packageهای مهم Weka مانند Filters، Classifiers، Clusterers، Associations، و Selection Attribute در Explorer به همراه یک ابزار Visualization این امکان را فراهم میکنند که Data Setها و پیشبینیهای مربوط به Classifierها و Clustererها در دو بعد به صورت بصری ارائه شوند. جریان پیشبینی Test Coverage در Weka Explorer به شکل زیر است:
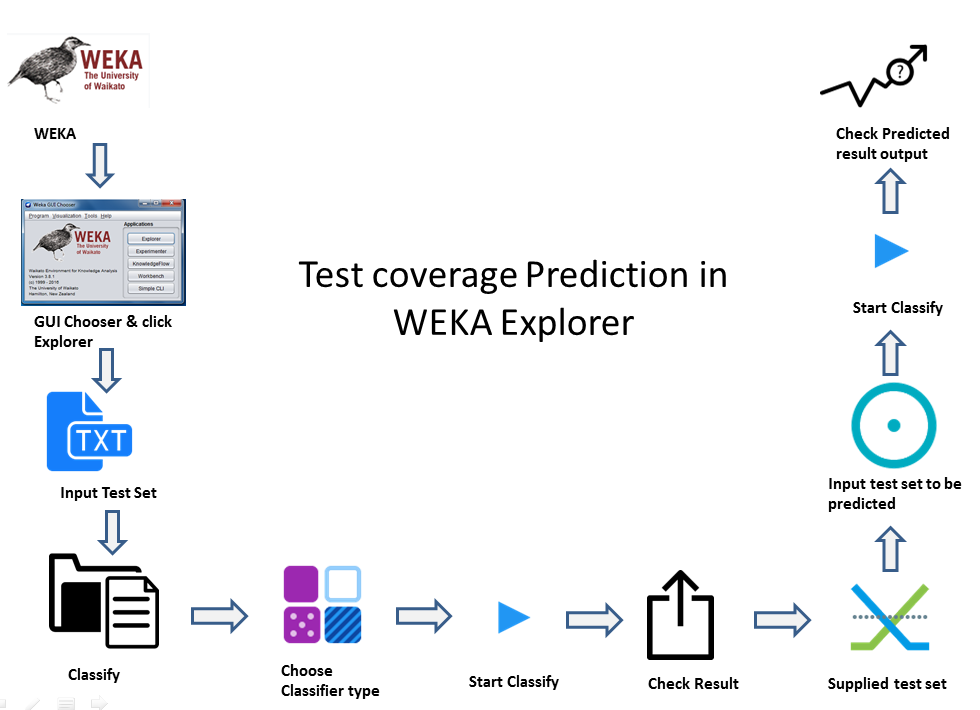
ما دادههای قدیمی مربوط به معیارهای Test Coverage را در فایلهای اکسل نگهداری میکردیم. حال به منظور ارزیابی دادهها، از یک فایل ARFF. به عنوان منبع داده(Data Source) استفاده کرده و فایل را با دادههای موجود در پروژههایمان آماده میکنیم. پس از مقداردهی فایل، عملیات مربوط به کلاسبندی(classification) را انجام میدهیم. این فرآیند به عنوان Training با دو مجموعه داده(Data Set) شناخته میشود. ما نتایج بدست آمده از آموزش را تجزیه و تحلیل کرده و صحت و دقت نتیجه را بررسی میکنیم. در واقع وقتی که قصد آموزش سیستمی را داریم، باید فایل ARFF. را با دادههای پیشبینی شده آماده کنیم.
در اجرای اول، دقتِ کار ضعیف و در حدود ۱۰% بود. در این راستا جلسهای تشکیل داده و به بررسی نتایج پرداختیم. بعد از آن، فرآیند Training را با چند مجموعه داده به انجام رساندیم و دقت پیشبینی Test Coverage را تا حدود ۷۰% افزایش دادیم.
در این مرحله، مدل بدست آمده را برای استفاده مجدد و صرفهجویی در زمان، ذخیره کردیم. از آنجاییکه مدل ذخیره شده موجود به راحتی در دسترس بود، ما آنرا لود نموده و سپس فایل مجموعه تست ARFF. را آپلود کردیم تا مورد پیشبینی قرار گیرد.
ما میتوانیم مدلهای ذخیره شده در Weka را بارگذاری کرده و آنها را با مجموعه دادههای جدید بررسی کنیم، و پیشبینیهای به روز رسانی شده را اطلاعرسانی نماییم. این موضوع کمک میکند تا دادهها زودتر از زمان برنامهریزی شده به ذینفعان پروژه ارائه گردند. علاوه بر این میتوان پیشبینیهای مربوط به برآورد پروژه و اشکالات را نیز با همان دقت انجام داد.
Weka شما را قادر خواهد ساخت تا به پیشبینی Test Coverage خود پیش از چرخه حیات توسعه نرمافزار بپردازید و بدین ترتیب زمان تحویل پروژه را بهبود دهید.


بسیار مفید ممنون از زحماتتون