نوشته های مرتبط




پیشبینی همیشه منجر به کاهش هزینههای احتمالی ناشی از یک حادثه و اتفاق شده و باعث صرفهجویی زمانی و مالی فراوان در هر حادثهای از هر نوع میشود. این موضوع در صنعت تست نرمافزار نیز حاکم است، که در آن تلاش میشود در انتهای یک بازه زمانی(مثلا مایلستون، اسپرینت یا …) باگهای احتمالی یا حداقل محل حضور باگ پیشبینی شود. این مقاله به موضوع پیشبینی باگ با استفاده از دادهکاوی خواهد پرداخت.
تقریبا نزدیک به ۱۰ سال پیش بود، که در یک شرکت نرمافزاری که محصولات Small Business تولید میکرد، مشغول به کار بودم. در اون زمان مبحث تست یک کار کاملا تجربی، و کلا فاقد یک نگرش علمی بود. هر چند که الان هم در بیشتر شرکتهای ایران و محیطهای تولید یا نظارت داخلی همین دیدگاه حاکم هست، اما در اون دوران تقریبا ذرهای نگاه علمی وجود نداشت. حتی خلاقیت هم در این زمینه خیلی کم بود.
خوب به خاطر دارم که با محصولی طرف بودیم، که تعداد بسیار زیادی مشتری داشت، و متاسفانه یک کد بسیار شلخته و اسپاگتی هم پشت سیستم بود، که باید نگهداری میشد. همین شلختگیِ کد باعث شده بود، که با یک محصول باگخیز مواجه باشیم. محصولی که من اصطلاحا مومیایی خطابش میکردم. چون به هر جاییش که دست میزدیم، ممکن بود مثل یک مومیاییِ چندهزار ساله ناگهان به خاک تبدیل بشه و از بین بره.
حالا تصور کنید که در زمان شاغل بودن من در این شرکت، نزدیک به چهل هزار مشتری محصول رو از ما خریداری کرده بودند، و تمامی اینها نیاز به پشتیبانی داشتند.
خوب با این اوصاف، معلومه وضعیت تیم فنی به چه شکلی هست. تیم توسعه به شدت درگیر، و تیم تست یک تیم کاملا تجربی(و البته ارزشمند)، که نه نگاه علمی به این ماجرا داشت و نه فرصت انجام این کار رو.
ماتریس تاثیرات
در اون دوره فکری به سرم زد، که بتونیم بر اساس اون، رخ دادن باگ در امکانات مختلف رو به دلیل اصلاح یا به روزرسانی یک امکان دیگه پیشبینی کنیم. با این کار میتونستیم به مرور زمان به یک دانش تجربی خوب دست پیدا کنیم، و براساس اون بعد از پیادهسازی یک امکان و تست اون، به سرعت به سراغ تست اون دست از امکاناتی بریم، که در ادوار قبل به دلیل به روزرسانی یا اصلاح امکان مذبور دچار مشکل شدند. برای انجام این کار در نظر داشتم که شاید بشه یک ماتریس بسیار دقیق(دو بعدی) از امکانات سیستم داشته باشیم، که سطر و ستون اول ماتریس شامل امکانات سیستم باشند. بعد هر خانهای از ماتریس که علامت خورد، به این معنی باشه، که تغییر در امکانات موجود در سرسطر ماتریس، امکانات موجود در سرستون رو دچار خلل یا ایراد کرده.
تقریبا شکلی مثل شکل زیر مد نظرم بود(F به معنی Feature یا امکان هست – در ادامه توضیح میدهیم که منظورمان از امکان در آن زمان خیلی شفاف نبود):
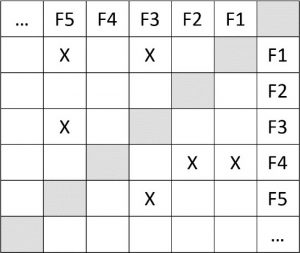
عوامل شکست ماتریس تاثیرگذاری
اما این کار به دلایل زیر به سختی قابل عملیاتی کردن بود:
- مشخص نبود، که برای ثبت هر امکان آیا باید آنها را در سطح یونیت یا ماژول در نظر میگرفتیم و یا باید سطح بزرگتری مثل Use Case را مد نظر داشته باشیم.
- گاهی اوقات تیم پشتیبانی مجبور بود، برای برطرف کردن یک ایراد دو یا سه قسمت(امکان) را دستکاری کند، و در این صورت ماتریس ما پاسخگو نبود.
- از آنجاییکه این ماتریس باید مرتب به روز میشد، احتمالا پس از مدتی تمام یا اکثر خانههای آن علامتگذاری میشد و ماتریس کارایی خود را از دست میداد.
- شاید در این ماتریس دادههای تاثیرگذاری به دقت درج شوند، اما آهنگ این تاثیرگذاری مشخص نیست. مثلا ممکن است طی ۱۰۰ بار کاری که روی F1 انجام شده است تنها ۲ بار روی F3 تاثیر منفی گذاشته باشد، اما در مقابل ۷۳ بار تاثیر منفی روی F5 داشته است. اما همانطور که در ماتریس بالا میبینید برای تاثیری که F3 و F5 از F1 پذیرفتهاند، تنها علامت X ثبت شده است. بعلاوه ما نمیتوانستیم چند ماتریس داشته باشیم، چون:
- لازمه داشتن چند ماتریس این بود، که ماتریس در دورههای زمانی خاصی تولید شود، مثلا در پایان هر مایلستون. اما در این شرکت توسعه و پشتیبانی بسیار بی نظم بود، و به صورت تواَمان پیش میرفت. درشتترین واحد کاری یک Task بود. Taskای که باید طبق زمان انجام میشد(هیچ Iteration، مایلستون، اسپرینت یا واحد دیگری که یک مجموعه Task هدفمند را در بر بگیرد وجود نداشت).
- هدف ما از ایجاد این ماتریس بدست آوردن یک مدل ساده تاثیرگذاری بود. در حالیکه وجود چند ماتریس باعث میشود استخراج یک مدل تاثیرگذاری بسیار پیچیده شود.
- از آنجاییکه فرآیند توسعه و پشتیبانی به صورت تواَمان انجام میشد، اطلاعاتی که در ماتریس ثبت میشد، از همگنیِ مناسبی برخوردار نبود. چرا که بعضی از آنها متعلق به امکانات اصلاح شده و به روز شده بود و برخی دیگر متعلق به امکانات جدید. از طرف دیگر ایجاد یک ماتریس جدید، برای امکانات اضافه شده، کارایی نداشت، چرا که امکانات در نسخه یک فقط جزءِ امکانات جدید محسوب میشوند و پس از آن در زمرهی امکانات تحت پشتیبانی حساب میشوند.
البته مسائل دیگری هم بود، که ذکر تمام آنها از حوصله مقاله خارج است.
این طرح در آن زمان علیرغم اینکه یک طرح خلاقانه جالب به نظر میرسید، اما به دلایل مذکور در بالا عملیاتی نشد و شکست خورد.
ماتریس تاثیرگذاری و دادهکاوی
مدتی بعد به شرکت دیگری رفتم. در شرکت جدید مسائل تست با شرکت قبل فرق داشت. علاوه بر اینکه نیازمندیهایشان در تست مقداری معقولتر از شرکت قبلی بود. زمانیکه وارد شرکت جدید شده بودم، مباحث Data Mining به تازگی مطرح شده بود، و تا جاییکه متوجه شده بودم معنی حدودیِ آن کند و کاو در دادههای مختلف، برای به دست آوردن مدلها و الگوهای پنهانیست که بدون دادهکاوی استخراج آنها تقریبا غیر ممکن است. همینجا بود که فکر جالبی به سرم زد و مقداری در مورد دادهکاوی و تست نرمافزار در اینترنت جستجو کردم. در آن زمان موضوع دادهکاوی بسیار جدید بود، و مقالات بسیار کمی در مورد دادهکاوی و تست نرمافزار وجود داشت. از آنجاییکه این موضوع در آن زمان جزء الزامات کاری من نبود، آنرا رها کردم. تا اینکه مجددا چند وقت پیش دو دانشجوی عزیز در این باره از من راهنمایی خواستند. زمانیکه در این مورد تحقیق کوتاهی کردم، مقالاتی دیدم که برایم بسیار جالب بود. جالبترین آنها مقالاتی بودند که دقیقا به موضوع پیشبینی(Prediction) نواقص با استفاده از دادهکاوی اشاره داشتند.
این موضوع دقیقا همان موضوع ماتریس تاثیرگذاری بود، که البته به شکلی بسیار پیشرفتهتر و وسیعتر ارائه شده بود. ما در ماتریس تاثیرگذاری قصد داشتیم تا پس از اصلاحات صورت گرفته روی کد، و تست آنها به مرور زمان به یک مدل از ایرادات و نواقص برسیم، تا به محض دستکاری شدن یک امکان به سرعت به سراغ قسمتهایی برویم که طبق ماتریس احتمالا دچار مشکل شدهاند. ما با این ماتریس این قابلیت را داشتیم که ایرادات و نواقص موجود در سطح دیگر امکانات و قسمتها را با احتمال نسبتا خوبی پیشبینی کنیم.
دادهکاوی برای پیشبینی نواقص
جهت آغاز دادهکاوی برای پیشبینی نواقص، شما نیازمند یک Bug Repository به عنوان منبع اصلی برای ماژولهای مستعد Fault هستید. آنچه در یک Bug Repository اهمیت فراوان دارد، قسمتهای اصلاح شده یا ایجاد شده و نیز باگهای بُروز کرده در زمان تست میباشند. این اطلاعات در ادوار مختلف زمانی جمعآوری شده و اطلاعات Repository را به مرور زمان غنیتر میکنند. طبعا این Bug Repository به لیست Taskها، Feature Version و دادههای دیگری متصل است، که بدون وجود آنها دادهکاوی یا قابل انجام نیست، و یا از دقت کمی برخوردار خواهد شد.
الگوریتمهای متفاوت داده کاوی برای استخراج ماژولهای مستعد Fault از این Repositoryها استفاده میشود. اما آنچه درباره دادهکاوی روی Repositoryها مطرح است، هم شیوههای علمی این کار و هم تکنولوژیهای مربوطه در این مورد میباشد.
Bug Trackerها
در زمان انتخاب تکنولوژی باید به خاطر داشته باشیم که موضوع داده کاوی روی باگها، الزاما در مورد Repositoryهای بزرگ ابزارهای Bug Tracking(که اصطلاح دیگر آن Defect & Change Management) قابل اجراست، چرا که حجم دادهها باید به میزان قابل توجهی برسد تا بتوان با استفاده از آنها یک مدل قابل اعتماد استخراج نمود. به هر اندازه که تست در شرایط غیریکسان بیشتری انجام شده باشد و اطلاعات بیشتری از تستها ثبت شده باشد، مدل استخراج شده توسط داده کاوی از دقت بیشتری برخوردار است. ابزارهای زیادی در زمینه Bug Tracking وجود دارند، از این دست ابزارها میتوان به:
Bugzilla, CodeProfiler – ABAP Code Scan, Enterprise Tester, Flyspray, Jira, Manits, McCabe CM, Meliora Testlab, Rational Change, Rational ClearQuest, Rational Functional Tester, Redmine, Roundup, SCM-Manager Universe, TestBench, Testersuite, Testomato, Trac, TRACE-CHECK, TEST-GUIDE, Trackplus اشاره نمود.
نمونهای از ابزارهای Data Mining روی Bug Repositoryها
زمانی که یک Bug نرمافزاری شناسایی میشود، ابتدا گزارش شده و سپس با استفاده از ابزارهای Bug Tracking در یک Bug Report Database ثبت میشود، تا بدین ترتیب بتوان تحلیل یا تعمیر بیشتری را روی آن انجام داد. در دنیای واقعی نرمافزارها، مقدار زیادی از Bug Reportها به مرور زمان در Bug Report Databaseها انباشته میشوند. به عنوان نمونه از فوریه سال ۲۰۱۱ بیش از ۶۱۵۰۰۰ گزارش Bug روی Debbugs-Debian Bug Tracking System ذخیره شده است.
ممکن است این Bug reportهای انباشته شده شامل اطلاعات ارزشمندی باشد که بتوان از آنها برای بهبود کیفیت Bug reporting، کاهش هزینه QA، تحلیل Software Reliability، و پیشبینی نواقص استفاده نمود. یکی از چالشهای موجود در گزارشگیری Bug این است که Bug reportها اغلب ناقص هستند(مثل مفقود شدن Data Fieldها مانند Product Version یا جزییات سیستم عامل مربوطه). یکی دیگر از چالشها هم معمولا وجود چندین Bug Reportهای برای یک Bug است. طبعا توسعهدهندگان نرمافزار یا تسترها باید این Bug reportهای مضاعف را به صورت دستی بازبینی کنند، که خود مستلزم زمان و هزینهایست که میتوان برای کارهای موثرتر صرف نمود.
یکی از ابزارها در این زمینه BUGMINER است که قادر به استخراج اطلاعات مفید از گزارشات باگ موجود از گذشته تا به امروز است، و این کار را با استفاده از تکنیکهای دادهکاوی، مشتمل بر Machine Learning(مانند SVM) و NLP-Natural Language Processing انجام میدهد. BUGMINER از این اطلاعات برای انجام Completion Check از طریق دستهبندی(Classification) و Redundancy Check از طریق Similarity Ranking روی یک Bug Report جدید یا موجود استفاده میکند. علاوه بر این BUGMINER میتواند تحلیل روند Bug Report را با استفاده از Weibull distribution انجام دهد. این ابزار پیادهسازی شده و با استفاده از سه جور Bug Report Repository در دنیای واقعی مورد آزمایش قرار گرفت، که عبارتند از: Tomcat، Eclipse، و Linux Kernel. آزمایشات صورت گرفته نشان داد که این ابزار برای پیادهسازی و اجرا ساده بوده، و با وجود دادههای کم کیفیت از دقت نسبتا بالایی برخوردار است.

